
采集链接方法1:css采集
在css选择器中基本表示用法:
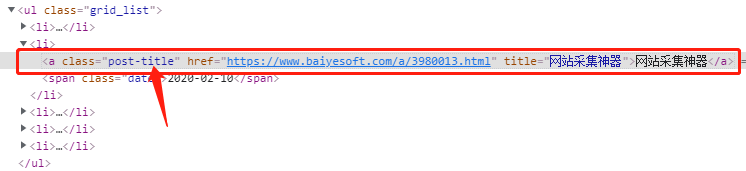
class值,用 . 表示,比如 .post-title
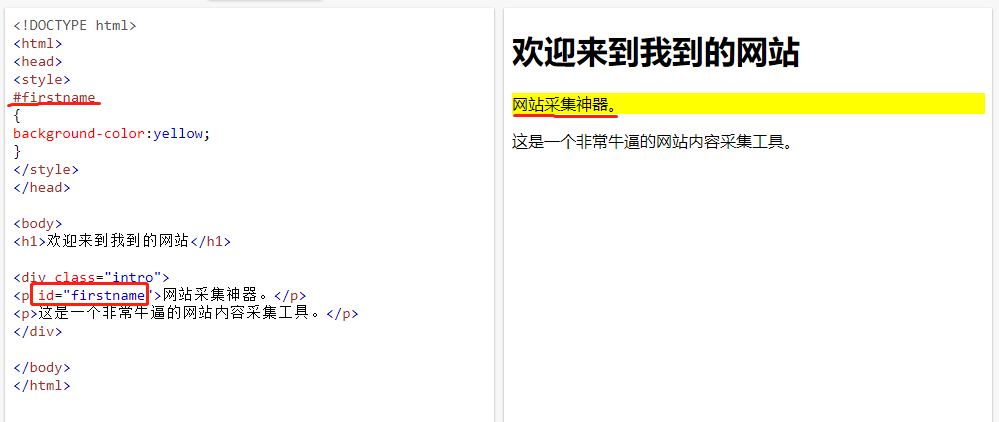
id值,用 # 表示,比如 #main
元素标签直接用标签名表示,比如h1标签,就是 h1
更多用法详见:css选择器参考手册
定位元素几种简单方法:
父元素选择器+空格+子元素选择器 比如:#main .post-title,#main .entry h2 a,.entry .post-title
父元素选择器+字元素名+子元素选择器 比如:#main a.post-title,.entry a.post-title
这几种方式,都可以定位到上图中的链接。
最终的元素必须得是a标签,在采集时会获取该标签的href值
如果还是不了解如何使用css代码,这里可直接输入一个 a,先定位页面中所有的超链接,再配合“链接过滤”来达到链接匹配。
采集链接方法2:正则匹配
1、正则匹配比css选择器稍微简单一点,找到需要采集的a标签,如:<a href="https://www.baiyesoft.com/a/3980013.html" title="网站采集神器">网站采集神器</a>

2、复制到正则表达式里,将不固定的内容都换为 [^>]*?,将href内容用()套上,([^>]*?),如下:
<a href="([^>]*?)" title="([^>]*?)">([^>]*?)</a>

正则表达式中的 / 前面都要加一个反斜杠 \
如果匹配到了多余的链接,可以用“匹配第几个”来排除 比如:
只需要匹配结果的第1个到第10个,输入 1-10
只需要匹配结果的第2个最后一个,输入 2-
当然也可以“链接过滤”的方法,排除掉不相关的链接。







