
【评论采集】
1、添加标签,所采集的评论标签名必须为 评论

数据格式:
1、纯文本。
2、带html代码。
注意事项:在采集时,前者会删除html代码,而后者不会。一般情况下,如果是评论采集,采集“评论”选择 纯文本或者采集“评论”选择 带html代码都可以,根据实际情况看。
评论内容匹配
评论内容匹配支持三种方式:
1、css选择器。
2、前后截取。
3、正则匹配。
注意!这三种方式是三选一,并不是同时有效。
css选择器
在css选择器中基本表示用法:
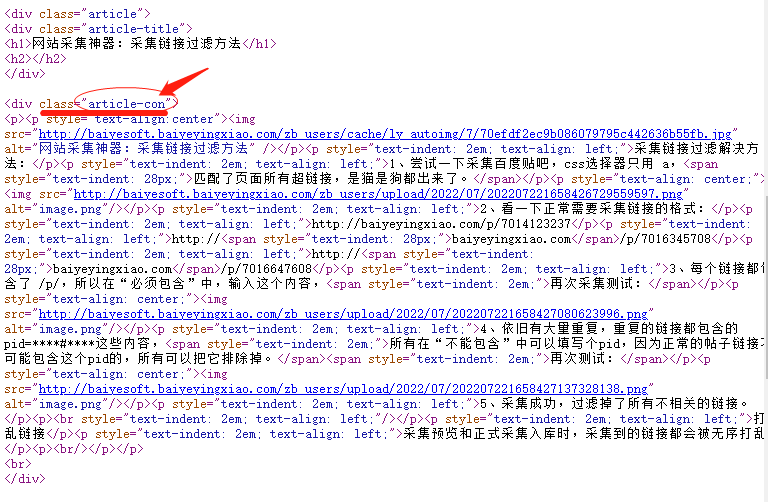
1、class值,用 . 表示,比如 .article-con,如下图:
2、id值,用 # 表示,比如 #main
3、元素标签直接用标签名表示,比如h1标签,就是 h1
更多用法详见:css选择器参考手册
定位元素几种简单方法:
1、父元素选择器+空格+子元素选择器 比如:#main .post-title,#main .entry h2 a,.entry .post-title
2、父元素选择器+字元素名+子元素选择器 比如:#main a.post-title,.entry a.post-title
注意事项:如果匹配到了多个评论内容,默认情况下,在入库时,会将这些评论内容依次首位相连合并。
前后截取
必须得有两段文本才能实现截取,开头字符串 和 结尾字符串,并且每个要采集的页面中,都必须包含这些字符,否则将会采集失败。该匹配评论内容的方式仅支持截取一段评论内容。开头字符串 必须是在html源码中第一次出现。注意事项:用作截取的评论内容,可以是任意字符,长度不宜过长。

排除元素
将已匹配到的评论内容,再次实行内容过滤,这里仅支持css选择器,多个选择器用英文 ,分开。
如果是过滤评论图片,直接在CSS选择器中输入:img 即可。
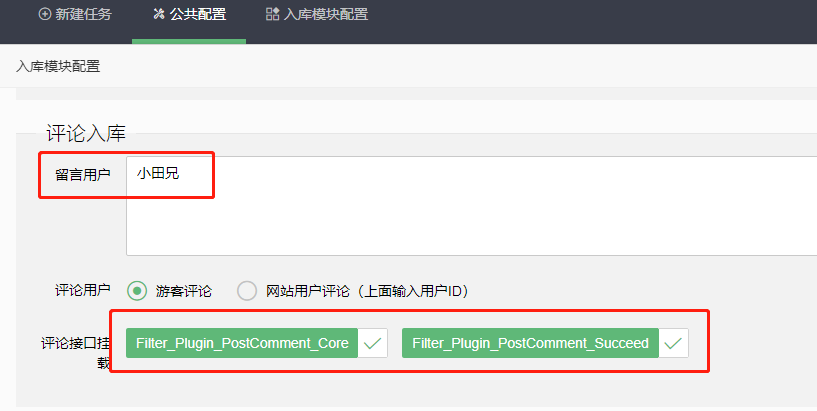
2、评论入库模块配置:
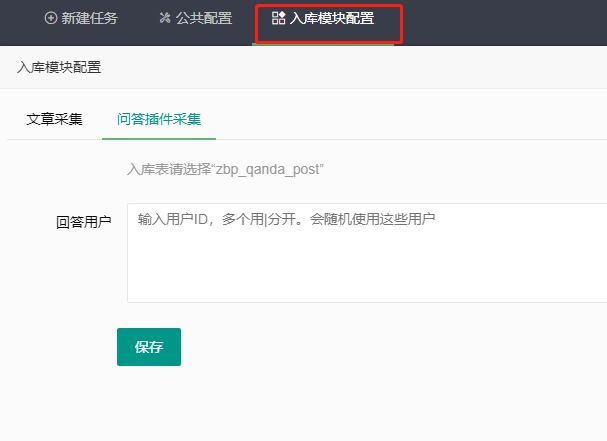
3、采集发布评论时,回答用户配置:
4、全部设置好,即可像采集文章一样开始采集即可。






